Data and AI Training
Home | Prices | Contact Us | Courses: Power BI - Excel - Python - SQL - Generative AI - Visualising Data - Analysing Data
How does Generative AI work?
This section describes how generative AI work under the covers. You don’t need to know this to use LLMs effectively but it helps to understand the reasons for their strengths and weaknesses. Most of the AI assistants we use in this course are based on large language model (LLM).
Large Language Models
A large language model (LLM) is a type of Generative AI program designed to understand, generate, and interact with human language. It is trained on vast amounts of text data. An LLM uses statistical analysis and language modelling techniques to repeatedly predict the next word in a sentence to build a response to a prompt.
It does not always choose the most probable next word. This is controlled by a setting named “temperature” If the temperature becomes warmer, the LLM is less likely to choose the most probable word and the output becomes more creative.
An LLM can answer questions, write essays, and create code. Here are a couple of useful terms
- prompt - input to the LLM, usually a sentence or paragraph
- completion - the output (or response) from the LLM
For example, here are three different completions of the next three words of a prompt “A tasty breakfast”
- could vary depending
- may include oatmeal
- includes scrambled eggs
Another example: given the prompt “She walked through”, possible continuations, with made-up probabilities, are:
- fire (10%)
- hell with a smile (5%)
- the park (3%)
- the fair (2%)
How to build a LLM
First step: self-supervised learning “guess the next word”
Download a lot of text (a corpus), preferably the entire internet.
Go through the next steps repeatedly for over the whole corpus in a process called self-supervised learning. This will cost $100m, takes several months and generate several hundred tons of CO2.
- Remove the last part of a sentence.
- Let the LLM guess / predict the continuations - the next word(s).
- Adjust the model to match the actual continuations (the ground truth). After a while the model gets really good at this “guess the next word” game.
Next step: Reinforcement learning with human feedback (fine-tuning)
At this point the model is pre-trained and will just continue / complete text. Now we fine-tune the model to make it useful. Humans provide questions and finetune the model so that it responds with something close to a model answer. Another technique to fine tune is for the LLM to generate two different answers. People then indicate which response they prefer and this is fed back into the fine training.
As the model grows in size, it shows surprising “emergent behaviours”:
- be able to crack jokes,
- provide step-by-step instructions,
- perform chain of thought reasoning,
- act in a role,
- write poetry,
- solve algebraic equations and
- provide strategic advice to directors of large organisations!
How LLMs work
An LLM is based on an AI approach known as deep learning. This uses a structure named a neutral net which looks like this.
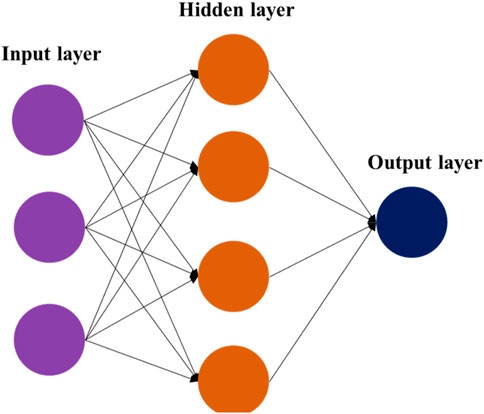
Source: https://www.frontiersin.org/files/Articles/1290880/fphy-11-1290880-HTML/image_m/fphy-11-1290880-g001.jpg
This contains nodes (or neurons, or simply numbers) and connections (lines, or sometimes called edges) between the nodes. The nodes are arranged in several layers:
- the input layer – the values of these nodes are set to the words at the start of the sentence
- several hidden layers – these help the neural net to generalise
- the output layer – the output of the nodes in this layer makes the prediction of the next word.
A node is connected to all the nodes in the previous layer by the connections. Each of these connections has a weight (a number) and it is these weights that are adjusted during the training so that the predictions and closer to the actual output values.
The node has an activation function that also determines the strength (weight) of its output based on the total of the weights of the input. (Typical ones are named RELU or Sigmoid). This activation function helps the LLM to generalise and learn.
The neural net in the diagram is tiny – it has about 30 parameters. Most neural nets are much bigger, Chat GPT has about 1 billion parameters, about the same as a rat brain, but currently less than a human brain (100 billion parameters). Size matters. Bigger is better.
Transformers
The transformer is a neural net architecture that has become the most popular approach in generative AI. The Transformer Explainer has a wonderful demo and explanation of transformers.
Tokenisation
LLMs work with numbers. Our prompt needs to be converted from text to numbers to be input into the model and the model output needs to be converted from numbers to text. A tokenizer converts text to a sequence (array) at numbers. The tokenizer splits text into an array tokens (roughly word/word fragment).
This page https://platform.openai.com/tokenizer from OpenAI shows what a tokenizer does.
The shortest history of Generative AI
Generative AI seems to have arrived suddenly but in fact it has a long gestation. Here are a few moments of AI history.
- 1956, Artificial Intelligence (AI) was born with the ambition to create intelligent machines at the Dartmouth Workshop
- 1990s, Machine Learning (ML), statistical learning from data and predictions.
- 2000s, commercial use of early single purpose Generative AI: Google Translate (2006), Siri (2011), autocomplete when texting on a phone
- 2017, deep learning, an ML technique inspired by the wiring in our brains takes off. In deep learning, “neurons” are connected into layers and the weights of the connections between neurons can be adjusted so that the neural net can “learn”.
- 2021, an extension of the neural net approach using a new “transformer” architecture yields results.
Given that long history, what is the reason for the recent excitement? These LLMs have very recently become much more powerful and capable. For example, in 2023, OpenAI released ChatGPT-4 which can do some very impressive things:
- score more highly on the SAT, a US-based university entrance exam, better than 90% of people,
- pass some university level exams in law, medicine,
- set out arguments in favour and against a certain thing e.g. vaping,
- play an expert role e.g. act a a Python expert and write code,
- write a job description.
Anybody can use ChatGPT and with a few hours training can use it very effectively - no coding proficiency or technical skills are required.
Because of these factors, ChatGPT took only 2 months to reach 100m users, compared to 9 months for TikTok and 70 months for Uber.