Data and AI Training
Home | Prices | Contact Us | Courses: Power BI - Excel - Python - SQL - Generative AI - Visualising Data - Analysing Data
GenAI Model 101 - The most popular models and their capabilities
Here is a whirlwind tour of the most popular generative AI models and their capabilities
The most popular models are:
- ChatGPT from Open AI
- Copilot from Microsoft is built into their products, notably Teams, PowerPoint, Excel, Word, Outlook
- Gemini, Flash, NotebookLM (for RAG purposes) from Google
- Claude from Anthropic
- Grok FROM xAI
- perplexity.ai
This is not an exhaustive list. These are all proprietary models - only available through an access mechanism (usually a web site or API) from the company that built the model. The internal details of how the model works or how it was trained are generally not known.
Capabilities of these models
For all models, we provide a prompt and receive a response.
Most times we interact with an AI assistant through its website or app. This looks like a stripped down user interface but in fact provides many features and capabilities. This is a user interface wrapper that allows access and interaction with a model but does much more than simply a direct go-between passing the prompt to the model and displaying the results. For example the proprietary models may have several extra tools and capabilities. These include:
- search
- code (Python) interpreter
- availability of reasoning models
- advanced voice mode and other ‘modalities’
- the ability to upload files such as PDF
- custom versions specialised for a particular task
The list of capabilities and the models offered depends on the provider and the pricing tier. For example, as of March 2025 ChatGPT has three pricing tiers described here, each with a different set of capabilities. For example, we can often choose a model (either cheap, and fast or slower, more expensive but possible providing a better response)
The capabilities may differ slightly between web and mobile (app) versions. For example, the ChatGPT app has the (very impressive) feature that users the camera on the mobile device and can describe what it sees. This is not available in the web version.
Search
During the training, models have “read” the content of the internet. They remember (vaguely) this content - and more so if a particular content appears many times in various places. However they have a knowledge cut-off date, and they have no knowledge of events more recent than this.
For some prompts, it is useful to ask the model to search the web. The model will do a web search and copy/paste any relevant results invisibly into the prompt. This way the response is more likely to be accurate and relevant. We can initiate a search by:
- clicking on a “Search” button in the prompt area, if there is one
- include in our prompt instructions to “Search the web and…”
Sometimes, the model knows from the nature of the prompt that it needs to search the web and so will do that without a specific instruction.
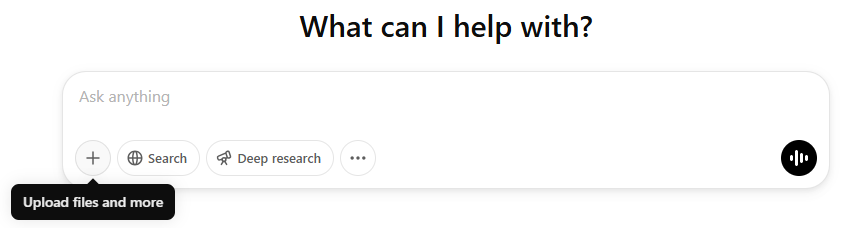
The ChatGPT prompt box with the Search (and also Deep research and advanced voice) buttons.
Code (Python) interpreter
AI models “remember” facts but this does not include the result to every calculation. Often for a coding or math problem, the models will invoke a code interpreter. It is able to write the code for the calculation, then run that code, then incorporate the result of that code execution in its response. This is a much more robust way of getting an accurate answer.
AI models use their code interpreter on many occasions: for example
- when asked to analyse some data
- when presented with a complex calculation
- when an instruction such as “use Python” is included in the prompt
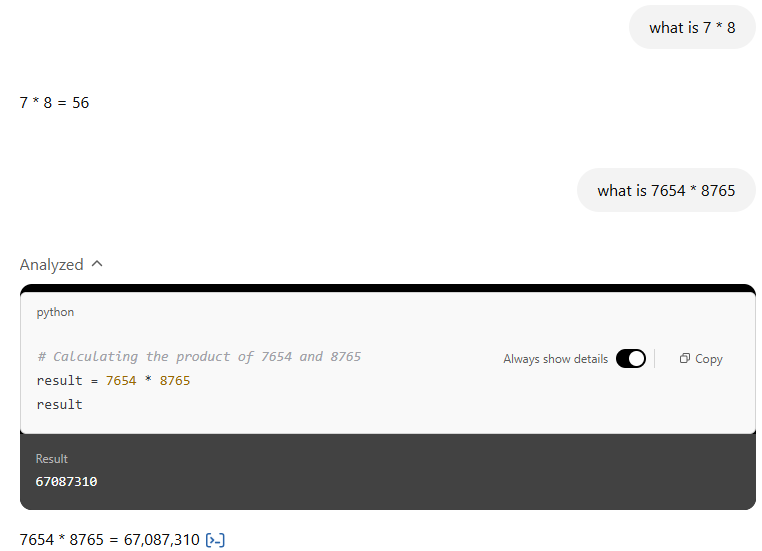
ChatGPT remembers the result of the simple multiplication but uses the code interpreter for a more complex multiplication.
Advanced voice mode and other ‘modalities’
Most models are able to “read aloud” - they can convert the response text into good quality audio speech.
Some models e.g. ChatGPT have an advanced voice mode. They will listen to the users’ prompts and speak the response. The model is responding to an audio speech prompt and directly providing a speech response. It is not using text as an intermediate part of this process (apart from transcribing into text after the fact if required). In this way a conversation can be very fluid, similar to a real conversation.
The ability to upload files such as PDF
With some models we can upload files such as PDF documents or Excel spreadsheets. The contents of these will be included in any prompt.
Custom versions specialised for a particular task
ChatGPT offers custom GPTs. These are models specialised for certain tasks. There is a gallery of pre-made custom AIs (tutor, image creator). It is also possible to create a custom GPT by provided details of the knowledge and the tasks in prompts.
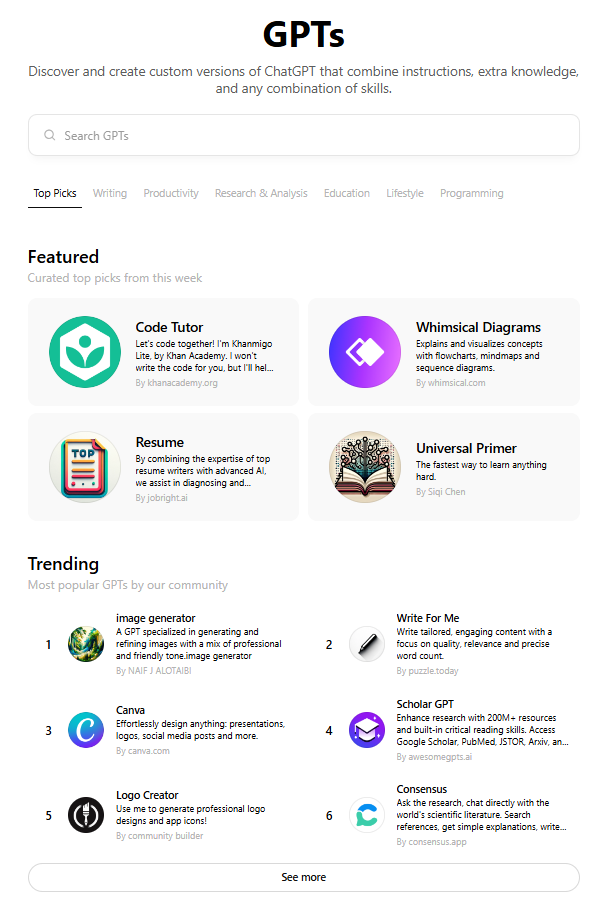
ChatGPT’s list of custom GPTs.
Availability of reasoning models
Reasoning models, also known as chain-of-thought models, are the latest models. They first split a complex prompt into a series of tasks and then attend to each task in turn, then put it all together. In this way, they can solve more difficult problems. They may also show their working.
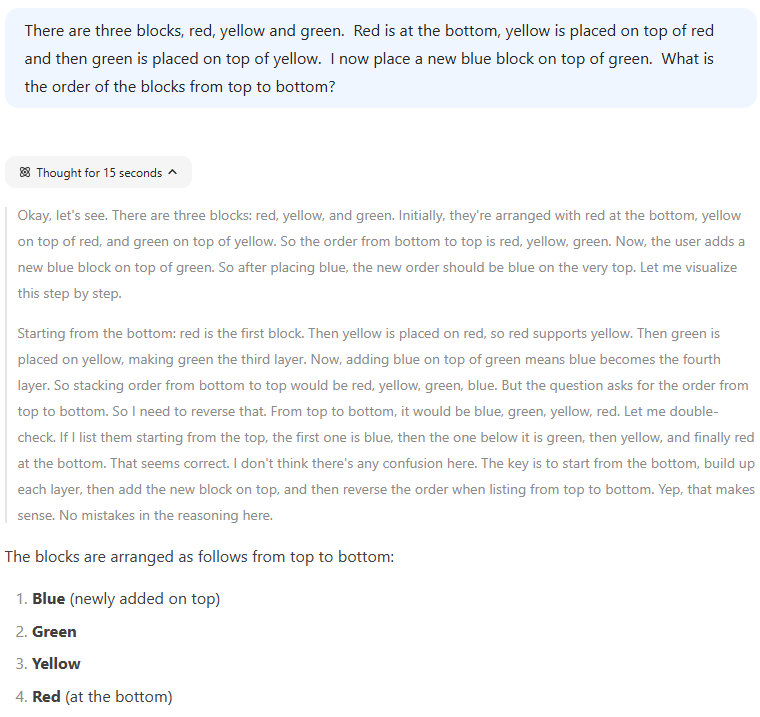
Deepseek thinking.
Settings and Memory
ChatGPT also has a memory feature where it infers and record details about the user based on information provided in the prompt. users can view the facts in the memory, delete if necessary and switch the memory off
AI assistants remember our chat history. ChatGPT has a “Projects” feature where we can organise our chat history into projects, for example based on different topics.
We can customise the app with system settings. We can explicitly provide instructions how to respond (e,g informally, briefly) to all prompts. We can, if we wish, tells the app some details about ourselves that it will take into account in its responses.
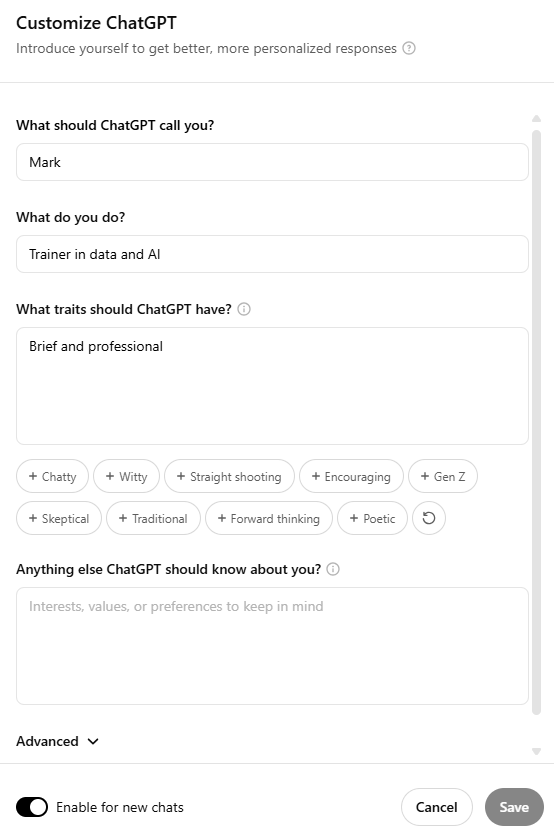
ChatGPT Settings
Canvas Mode
There are various modes of operation. For example, ChatGPT’s Canvas mode splits the screen, put the prompt / response on the left and the document being worked on the right. This allows a more collaborative approach between user and AI assistant. Within the Canvas mode, ChatGPT models can write code, especially Python, and run it for us.