Data and AI Training
Home | Prices | Contact Us | Courses: Power BI - Excel - Python - SQL - Generative AI - Visualising Data - Analysing Data
GenAI Model 104 - Generative AI Terms
AI models come in all shapes and sizes. Here is my attempt to classify them and to explain some of the terms.
Size of the model
This refers to the number of parameters in the model. This typically varies between 1 and 700 billion parameters. The larger models take more time and resources to process a request but will probably give a better response. Often for simple prompts, a smaller model is sufficient. Often, a family of models will be published in a range of sizes. For example the deepseek-r1 model has seven different sizes. The smaller models may have been “distilled” for the large models
Parameters are adjustable knobs of the model set during training that help it to know (in a lossy way) the content of its source corpus (usually a cleaned up crawled copy of the internet.
Specialised models
Models can be specialised to be
- good for academic reference
- good at transcription. For example, Whisper, an open source model form OpenAI, can transcribe a conversation better than I ever could
- good for computer coding challenges (OpenAI’s Codex or Meta’s Code Llama)
- specialised for Retrieval Augmented Generation (RAG)
A RAG model answers questions based on the content of a set of documents provided - and only that content, not from general training. This is a useful use-case. When building the model, the documents are important, split into chunks of typically a paragraph. These chunks are put into a vector database. When preparing to respond to a prompt, the RAG model will do a semantic similarity search between the prompt and the chunks, add the 5 (say) most relevant chunks into the prompt template that also tells the AI assistant to use just this content
Ollama classifies specialised models as either embedding, visual or tools.
- Embedding models convert text or other data into numerical vectors: use cases include similarity search, clustering, and semantic understanding.
- Visual models process and generate images: use cases include object detection, classification, and image-to-text generation.
- Tool models integrate with external tools or APIs to extend functionality, such as running code, retrieving web data, or automating tasks.
Performance
There are a set of benchmarks for models. Different benchmarks measure different capabilities e.g. problem-solving, math, For example, Deepseek published its results on the standard benchmarks here …
Benchmarks should be taken as a general guide - the really important thing is how well a model works for you
Modality
Modality refers to the types of input and output, whether text, audio (speech or music), image or video
Models can take in data and respond in several formats (text, audi, images, video). Current examples include:
- text to image: such as Open AIs DALL-E, MidJourney
- audio to text e.g transcription in Microsoft Teams
- text to video for example, Open AI’s Sora
The apps and websites of many AI assistants are offering multi-modal features. For example, ChatGPT 4o transforms text to text, image to text (it can describe an image), text to image, and text to video. OpenAI demos GPT 4o as able to understand facial expressions and respond with a voice expressing emotion.
Tokenisation
LLMs work with numbers. Our prompt needs to be converted from text to numbers to be input into the model and the model output needs to be converted from numbers to text. A tokenizer converts text to a sequence (array) at numbers. The tokenizer splits text into an array tokens (roughly word/word fragment). Tokenisation maps each word or word-fragment into a number based on a given mapping. For example the Open AI Chat GPT 4 dictionary has about 100,000 tokens.
This page https://platform.openai.com/tokenizer from OpenAI shows what a tokenizer does.
For example the sentence
How many times does the letter r appear in raspberry, elderberry and strawberry?
is split as shown below (notice that elderberry splits into two tokens)

and the corresponding token IDs are
[5299, 1991, 4238, 2226, 290, 10263, 428, 7680, 306, 134404, 11, 33757, 19772, 326, 101830, 30]
The Tiktoktokenizer page is an interactive page - enter a prompt and it will show the corresponding tokens.
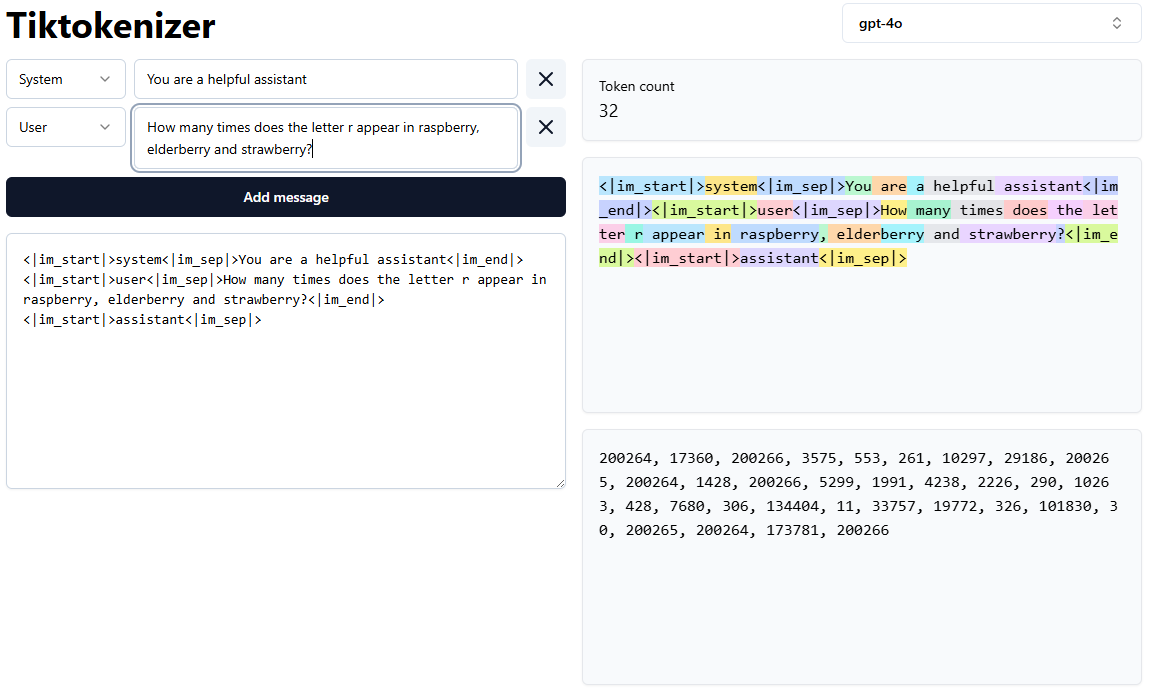
Note that in the gpt-4o model there are special tokens for the start and end of the system and user prompt. These are used in the supervised fine tuning (SFT) training to build the instruct model - an assistant that will respond usefully)