Data and AI Training
Home | Prices | Contact Us | Courses: Power BI - Excel - Python - SQL - Generative AI - Visualising Data - Analysing Data
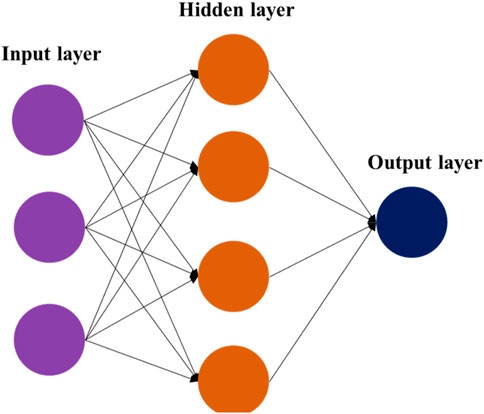
A generative AI model is based on an AI approach known as deep learning. This uses a structure named a neutral net which looks like this.
Source: https://www.frontiersin.org/files/Articles/1290880/fphy-11-1290880-HTML/image_m/fphy-11-1290880-g001.jpg
This contains nodes (or neurons, or simply numbers) and connections (lines, or sometimes called edges) between the nodes. The nodes are arranged in several layers:
- the input layer – the values of these nodes are set to the words at the start of the sentence
- several hidden layers – these help the neural net to generalise
- the output layer – the output of the nodes in this layer makes the prediction of the next word.
A node is connected to all the nodes in the previous layer by the connections. Each of these connections has a weight (a number) and it is these weights that are adjusted during the training so that the predictions and closer to the actual output values.
The node has an activation function that also determines the strength (weight) of its output based on the total of the weights of the input. (Typical ones are named RELU or Sigmoid). This activation function helps the LLM to generalise and learn.
The neural net in the diagram is tiny – it has about 30 parameters. Most neural nets are much bigger, Chat GPT has about 1 billion parameters, about the same as a rat brain, but currently less than a human brain (100 billion parameters). Size matters. Bigger is better.